Reinforcement Learning Notes: Theory and Algorithms
Taken on MRL course @ Universitas Indonesia [On progress]
Overview of the Field
Understanding Reinforcement Learning Categories is a Must. Reinforcement Learning (RL) spans a wide range of algorithms, each based on different assumptions, optimization principles, and feedback structures. Unlike supervised learning, the diversity of RL approaches—each requiring different theory, tools, and implementation strategies—makes the learning curve steep but rewarding.

Model-Based vs Model-Free: Availability of Transitions. A core distinction in RL is whether the transition dynamics—represented as $P(s’ \mid s, a)$, the probability of ending up in state $s’$ after taking action $a$ in state $s$—are known. In model-based RL (aka DP settings), these dynamics are known or learned and explicitly used to plan optimal behavior. In model-free RL (aka RL settings), we assume no access to this underlying probability, which reflects most real-world situations.
Model-Free RL: Learning Without Transition Knowledge. When we don’t know $P(s’ \mid s, a)$, we resort to model-free methods, which learn from direct interaction. These approaches can be further divided into:
- Gradient-Free Methods, where updates are not derived from explicit gradients.
- Off-Policy methods (e.g., Q-learning, DQN) learn an optimal policy (action determiner) from data generated by a different behavior policy, allowing better exploration.
- On-Policy methods (e.g., SARSA, TD learning) learn from and about the same policy, often with more stable but sample-inefficient updates.
- Gradient-Based Methods, such as Policy Gradient approaches, optimize expected cumulative reward via gradient ascent in the parameter space of a policy network. \(\theta_{new} = \theta_{old} + \alpha\nabla_\theta\mathbb E[R_{\Sigma, \theta}]\)
Deep RL: A Revolution in Expressiveness. Deep Reinforcement Learning integrates deep neural networks with RL algorithms to handle high-dimensional state and action spaces. Deep RL enable breakthroughs in games (e.g., Atari, Go), robotics, and complex control systems. Deep RL also blurs traditional boundaries, DQNs bring deep learning to value-based methods, while Actor-Critic methods combine policy gradients and value estimation. This integration brings power, but also introduces stability and sample efficiency challenges.
Problem Formulation: Markov Decision Process
This section is a personal revision on
that summarized a week lecture at University of Indonesia Machine Reinforcement Learning by Vektor Dewanto.
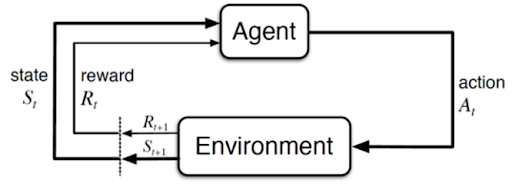
Formal Definition of MDP. The Markov Decision Process (MDP) is a foundational framework used across disciplines—from AI and control theory to economics and operations research. An MDP is defined as the tuple $M = (\mathcal S, \mathcal A, \mathcal T , \dot p, p, r)$, where:
- $\mathcal S$ is the state set, $S = {s^0, s^1, \dots, s^{\vert\mathcal S\vert}}$
- $\mathcal A$ is the action set, $A = {a^0, a^1, \dots, a^{\vert\mathcal A\vert}}$
- $\mathcal T$ is the time set, $\mathcal T={0, 1, 2, \dots}$, usually people skip this because mostly we only deals with discrete time
- $\dot p: \mathcal S\to [0, 1]$ is the initial state distribution, $\dot p(s)$ probability of starting at a $s$.
- $p:\mathcal S\times\mathcal A\times\mathcal S\to[0,1]$ is the transition function, defined as $p(s’\mid s, a)$, probability of ends in $s’$ given doing action $a$ in $s$
- $r(s, a)$ is the reward function, specifying the expected reward received for taking action $a$ in state $s$. Other form such $r(s’\mid s, a)$ is also possible and could easily converted by marginalization.
Remember that $s^0$ represent state 0, $s_1^0$ represent state 0 at time $t=1$.
Lets Assume Stationary MDPs for Simplicity. In this setting, the state and action sets remain unchanged over time, and our goal is to find a stationary optimal policy. Formally, this means. State space, Action space, transition probability, and reward function is independent of time.
\[\mathcal S_t = \mathcal S,\quad \mathcal A_t = \mathcal A,\quad p_t=p,\quad r_t=r\]This relaxation could be imagine in chess as, the available actions for any board configuration never change, which simplifies modeling. In contrast, non-stationary MDPs allow these components to vary over time reflects many real-world problem.
Assuming Infinite Horizon and Discrete Time. In addition to stationarity, we often assume an infinite time horizon (i.e., the agent interacts with the environment indefinitely) and discrete time steps. Finite-horizon MDPs are also studied especially in planning problems, but often lead to time-dependent policies. We also assume finite state and action spaces, which enables representations in finite computer’s memory and guarantees convergence.
Markovian: The Markov Assumption on Time Dependency. A core assumption of MDPs is the Markov property, which states that the future state depends only on the current state and action, not on the entire history. This simplifies the transition function to:
\[\Pr(S_{t+1}\mid s_t, a_t)\]rather than
\[\Pr(S_{t+1}\mid s_0, a_0, s_1, a_1, \dots, s_t, a_t)\]This also often called the first-order Markov assumption. While real-world scenarios often violate this assumption, we either redefine the state to be more informative or use memory-based models (e.g., RNNs in Deep RL) when necessary.
MDP Visual Interpretation. A helpful intuition for this is shown in the diagram below. The agent transitions between various states like “Wake Up”, “Netflix”, “Code & Debug”, and “Deploy”, receiving different rewards depending on its action.
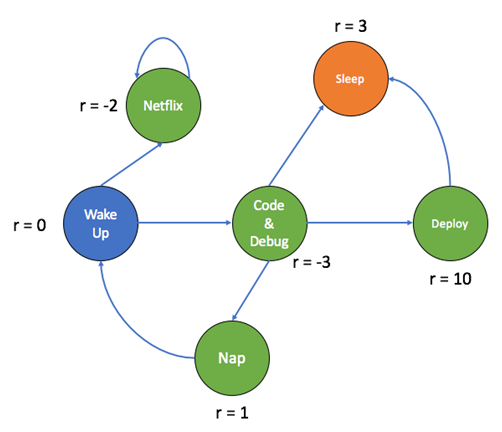
This environment is Markovian: the next state and reward depend only on the current state and action—not on how the agent reached that state. For example, regardless of whether the agent arrived at “Code & Debug” from “Nap” or “Wake Up”, the outcome of choosing “Sleep” will always transition to “Sleep” with a reward of 3.
Policy: The Solution to the MDP. Policy $\pi:\mathcal S\times \mathcal A\to[0, 1]$ defines the agent’s behavior by specifying the probability of choosing each action in each state.
\[\pi(a\mid s)=\Pr(A_t=a\mid S_t=s)\]There are two main classes of policies:
- $\prod_{SR}:$ Represent set of Stationary Randomized/Stochastic policies.
- $\prod_{SD}:$ Represent set of Stationary Deterministic policies, one action with probability 1, will always be chosen.
A deterministic policy $\pi_{SD}\in\prod_{SD}:\mathcal S\to\mathcal A$ maps single state to single action. It can be viewed as a special case of stochastic policy.
\[\pi(a\mid s) = \begin{cases} 1\quad\text{if }a=\pi_{SD}(a) \\ 0\quad\text{otherwise} \end{cases}\]Showing that $\prod_{SD}\subset\prod_{SR}$
Matrix Representation of a Policy. A policy can also be represented as a matrix, where each row corresponds to a state and each column corresponds to an action: \(\pi = \begin{bmatrix} \pi(a^0\mid s^0) & \pi(a^1\mid s^0) & \dots & \pi(a^{\vert\mathcal A\vert}\mid s^0) \\ \pi(a^0\mid s^1) & \pi(a^1\mid s^1) & \dots & \pi(a^{\vert\mathcal A\vert}\mid s^1) \\ \vdots & \vdots & \ddots & \vdots \\ \pi(a^0\mid s^{\vert\mathcal S\vert}) & \pi(a^1\mid s^{\vert\mathcal S\vert}) & \dots & \pi(a^{\vert\mathcal A\vert}\mid s^{\vert\mathcal S\vert}) \\ \end{bmatrix} \in R^{\mathcal \vert S\vert \times\mathcal \vert A\vert}\)
We see that in ith-row, $\pi(\cdot, s^i)$, represent action distribution at state $s^i$, the best action is the maximum among this rows. Please also note that sum over actions must be one $\sum_a \pi(a\mid s)=1$.
Markov Chain: Unique Action MDP. Every MDP with a fixed policy $\pi$ induces a Markov Chain (MC). A Markov Chain is an MDP where each state has a unique action. Because $p(s’\mid s, a)$ and we fix $\pi$, $p(s’\mid s, \pi(s)):\mathcal S\times\mathcal S\to[0, 1]$ could be derived called stochastic transition matrix or one-step state-transition matrix denoted as $P\in R^{\vert\mathcal S\vert\times\vert\mathcal S\vert}$ matrix. Formally
\[\begin{align} P_\pi(s_{t+1}\mid s_t) &= \mathbb E_{a\sim \pi}[ p(s_{t+1}\mid s_t, a) ] \\ P_\pi(s_{t+1}\mid s_t) &= \sum_{a\in\mathcal A} \pi(a\mid s_t)\cdot p(s_{t+1}\mid s) \\ P_{\pi, ij} = P_{ij} &= P_\pi(s_j, s_i)\quad\text{Matrix Form} \end{align}\]$P_{ij}$ describes the probability of ending at $s^j$ given current state $s^i$.
$P$ is stochastic meaning that
- Probability entries $0\le P_{ij}\le 1$
- $\sum_j P_{ij} = 1$, we will always ended up in one of state $s^j$ given current state $s^i$.
K-th Step Transitions. Given Markov Chain (fixed policy), the probability of ending at time k for all states $s_k$ could be computed as
\[P^k = P\times P\times \dots\times P\quad(k\text{-times})\]$P^k_{ij}$ now represent the probability of starting (at $t=0$) at $s_i$ and ended up in $s_j$.
State Classification in Markov Chain. Knowing class of a markov chain, we could assure the convergence of an algorithm. In Markov Chains (MC), states can be classified into two main categories:
- Recurrent: If the probability of returning to s from s is 1. This means that the state will be visited infinitely many times.
- Transient: If there is a non-zero probability of never returning to s. This means that the state might be left.
Markov Chains Classification. Some theorem will be based on implication of some markov chains class.
-
Recurrent Markov Chain: All states are recurrent, meaning that from any state it is possible to return to that state eventually. There are no transient states in a recurrent Markov Chain. EXAMPLE
-
Unichain Markov Chain: Contains a single recurrent class and possibly some transient states. A recurrent class is a set of states where each state can be reached from any other state within the class, and once entered, the process cannot leave the class. Transient states are those that, once left, cannot be returned to. EXAMPLE
-
Multichain Markov Chain: Contains more than one recurrent class. Each recurrent class is a set of states where each state can be reached from any other state within the class, and once entered, the process cannot leave the class. There may also be transient states that do not belong to any recurrent class. EXAMPLE
Theorem. In Finite MDP, there exists at least one chain.. We classify MDPs as follows:
- Unichain MDP: All induced MCs are unichain.
- Multichain MDP: At least one induced MC is multichain.
Markov Chains Limiting State Transition Matrix P. Denote $P_\pi^\star$ the limiting state transition matrix or converged transition after time.
\[P_\pi^\star = \lim_{k\to\infty} P^k\]Since computers cannot compute indefinitely until reaching infinity, we need practical methods to approximate $P_\pi^\star$. Here are two common approaches:
- Iterative method, we enumerate $k$ and stop for predefined constant or comparing converge tollerance $\Vert P^k-P^{k-1}\Vert_c < \epsilon$, for preference matrix norm $c$ and real threshold $\epsilon$.
- Close form solution,
\(\begin{align} (P_\pi^\star)^T P &= (P_\pi^\star)^T \\ (P_\pi^\star)^T P - (P_\pi^\star)^T &= \vec 0 \\ (P_\pi^\star)^T(P-I) &= \vec 0 \\ ((P-I)^T(P_\pi^\star))^T &= \vec 0 \\ (P-I)^T(P_\pi^\star) &= \vec 0 \end{align}\) with contraint of $P_\pi^\star$ is a stochastic matrix i.e
\[\sum_i^{\vert\mathcal S\vert} P_{\pi, i}^\star = 1\]Theorem. In Unichain Markov Chains, all rows of the limiting state transition matrix $P_\pi^\star$ are identical
\[P_\pi^\star = \begin{bmatrix} (p_\pi^\star)^T \\ (p_\pi^\star)^T \\ \vdots \\ (p_\pi^\star)^T \end{bmatrix}\]Then matrix $P_\pi^\star$ could be represented by single vector $p_\pi^\star$ that satisfy linear system of equations.
\[(P-I)^Tp_\pi^\star = \vec 0\]Because it is an overdetermined equation, the trick is to
- Replace the last row of $(P-I)^T$ with $[1\;1\;\dots\;1]$ and store it in matrix $A$.
- Replace the corresponding entry on the right-hand side (which was originally a zero vector) with 1.
- Solve the modified system to get the $p_\pi^\star$:
Optimality Criteria and Optimal Policies is the solution for Markov Reward Process (MRP)., MRP is a Markov Chain with an addition to transitioning between states based on a probability distribution, each state also has an associated reward. We need to measure with respect to some optimality criterion denote by $v(\pi, s)$. We parameterize startign state $s$ since starting state will sure affect the quality, more general form could easily derive from marginalizing over initial state distribution, $\mathbb E_{s\sim\dot p}v(\pi, s)$. We then could define the optimal policy is the one that maximize value function $v$.
\[\pi^\star = \arg\max_{\pi\in\prod_{SR}} v(\pi, s),\quad \forall s\in\mathcal S\]Theorem. In a finite MDP, an optimal deterministic policy $\pi\in\prod_{SD}$ exists. This means we could reduce the solution search into $\prod_{SD}$ domain which is finite, hence a brute force solution will exists with time complexity of $O(\vert\mathcal S\vert^{\vert\mathcal A\vert})$ (remember that deterministic policy is a function of state to action, we will generate every possible action in every possible state).
Kind of reward value function $v$. Note that all these value function is a function of policy and states. Given fixed policy $\pi$, the form of $v$ is actually a vector of size $\vert\mathcal S\vert$. Optimal policy is based on which value function (optimal criterion) is used.
- Total Value Function $v_{total}$.
Using this, as $t\to\infty$, $v_{total}(\pi, s)\to\infty$ which is unusable in infinite horizon MDP.
- Average Reward Function $v_g$.
This average reward can be calculated using these closed form formula obtained from converge transition probability along with the states reward.
\[\vec v_g(\pi) = P_\pi^\star r_\pi\]- Discounted Reward $v_\gamma$
The discount factor $\gamma$ ensures convergence by weighting future rewards less as they are further into the future.
- Bias Reward $v_b$
The summation term represents the immediate reward $r$ and $v_g(\pi)$ represents the long-term reward. Thus, their difference can be interpreted as a measure of bias. Derived from the Bellman Average Reward Evaluation Equation (BEE) that will be explained in the following paragraphs.
Theorem. In a unichain Markov Chain, all average reward for different state is the same.
\(v_g(s^0) = v_g(s^1) = \dots = v_g(s^{\vert\mathcal S\vert})\) This means that $v_g(s)$ does not depend on the initial state $\dot p$, so we only need to compute $v_g(s^0)$ once then define $\vec v_g = v_g(s^0) \cdot \vec 1 $
Form of Reward Function. Take a note that all these reward assume fixed policy $\pi$. And their form is using usual convention, stacking states as the first dimension.
- State action state general form
- State action form
- State based form
Best visualization for MDP. MDP intuitively could be imagine as a directred acyclic graph with an edge represent possibility.
Bellman Evaluation and Bellman Optimal Equation
Bellman Average Reward Evaluation Equation (BEE). Fundamental equation, the idea is to express immediate and future reward in one equation.
\[\begin{align*} v_b(\pi, s) + v_g(\pi) &= \mathbb E_{a\sim\pi}[r(s, a)+\mathbb E_{s'\sim p(\cdot\mid s, a)} v_b(s')] \\ v_b(\pi, s) + v_g(\pi) &= \mathbb E_{a\sim\pi}[r(s, a)+\sum_{s'\in\mathcal S} p(s'\mid s, a) v_b(s')] \end{align*}\]However, there are $\vert S\vert + 1$ unknowns with $\vert S\vert$ number of equations ($\vert S\vert$ of $v_b(\pi, s)$ (one for each state) and single unknown $v_g(\pi)$). This forms an under-determined Linear Equations that will be solved later in following paragraphs.
Making Under-Determined BEE Well-Determine. To solve the under-determined Bellman Average Reward Evaluation Equation (BEE) System of Linear Equations (SLE), we introduce an additional constraint by setting the bias of a reference state to zero.
- Choose a reference state, say $s^0$, and set its bias to zero: $v_b(\pi, s^0) = 0$
- Rewrite the formula
Closed-form Solution for $v_b(\pi)$. Remember that $v_g(\pi)=P_\pi^\star \vec r_\pi$. Using this definition, we could manipulate in matrix form then solve it directly.
\[\begin{align*} \vec v_b(\pi) + v_g(\pi)\cdot\vec 1 &= \vec r_\pi + P_\pi\vec v_b(\pi) \\ \vec v_b(\pi) - P_\pi\vec v_b(\pi) &= \vec r_\pi - v_g(\pi)\cdot\vec 1 \\ (I-P_\pi)\vec v_b(\pi) &= \vec r_\pi - P_\pi^\star \vec r_\pi \\ \vec v_b(\pi) &= (I-P_\pi)^{-1}(\vec r_\pi - P_\pi^\star \vec r_\pi) \\ \vec v_b(\pi) &= (I-P_\pi)^{-1}\vec r_\pi - (I-P_\pi)^{-1}P_\pi^\star \vec r_\pi \\ \vec v_b(\pi) &= [\,(I-P_\pi)^{-1}- (I-P_\pi)^{-1}P_\pi^\star\,] \vec r_\pi \\ \vec v_b(\pi) &= [\,(I-P_\pi)^{-1}( I - P_\pi^\star\,)] \vec r_\pi \\ \vec v_b(\pi) &= \left( \underbrace{(I - P_\pi + P_\pi^\star)^{-1} - P_\pi^\star}_{H_\pi} \right) \vec r_\pi \\ \vec v_b(\pi) &= H_\pi \vec r_\pi \\ \end{align*}\]Note that $H_\pi$ is not a stochastic matrix anymore.The last expression is derive using special case that $P_\pi^\star$ is a fixed point, this implies $(I−A)^{−1}(I−B)=(I−A+B)^{−1}−B$. Trust me you don’t want to see the proof, its really specific. I accept and trust this work from our ancesstor completely without any question. Ask gpt in case you need, he’s capable of deriving this.
Bellman Optimality Equation (BOE). Fundamental concept, it describes the relationship between the value of a state under an optimal policy and the expected return from that state. Optimality condition ensures the equation holds only to the optimal policy, denoted as $\pi^\star$. It is written as
\[v_b(\pi^\star, s) + v_g(\pi^\star) = \max_{a\in\mathcal A}\left[r(s, a) + \sum_{s'\in\mathcal S} p(s'\mid s, a)v_b(\pi^\star, s') \right]\]To derive the optimal policy $\pi^\star$, we first obtain optimal $v_b^\star$ and then greedily act wrt the righthand side (RHS) of BOE. Although there may be multiple optimal policies $\pi^\star$, there exists only a single optimal $v_g^\star$ and a single optimal $v_b^\star$.
BOE vs BEE.
- Applicability: BEE applies to all policies, whereas BOE applies only to the optimal policy.
- Action Selection: BEE computes the expectation over actions taken by a given policy ($\mathbb E_{a\sim\pi}(\cdot\mid s)$), while BOE selects actions that maximize the expected value ($\max_{a\in\mathcal A}$).
- Linearity: BEE is a linear equation because it averages over policy actions, whereas BOE is non-linear due to the maximization operator.
- Value Function Properties: BEE helps evaluate a policy’s value but does not necessarily lead to optimality. In contrast, BOE guarantees that the resulting value function is optimal when solved.
State Action Value Function
The Concept of State Action Value Function $q$. In model-free (RL settings), we don’t know the transition probability $p(s’\mid s, a)$, thus we introduce state action bias (aka state action) $q_b(\pi, s, a)=q_b^\pi(s, a)$ that could eliminate the need for transition probability.
BOE on State Action Value ($q_b$). The optimal action value function satisfies the equation:
\[\begin{align*} v_b^\star(s) &= \max_{a\in\mathcal A} q_b^\star(s, a) \\ q_b^\star(s, a) +v_g^\star &= r(s, a) + \sum_{s'\in\mathcal S} p(s'\mid s,a)\max_{a'\in\mathcal A}q_b^\star(s', a') \\ q_b^\star(s, a) +v_g^\star &= r(s, a) + \mathbb E_{s'\sim p(\cdot\mid s, a)}[v_b^\star(s')] \\ \end{align*}\]Thus the optimal policy can be derived as.
\[\pi^\star(s)\in\arg\max_{a\in\mathcal A} q_b^\star(s, a)\]Benefits of BOE for Action Values $q$ over State Values $v$.
- The optimal policy $\pi^\star(s)$ is greedy with respect to $q_b(s, \cdot)$
- $q_b$ incorporates the effects of $p(\cdot\mid s, a), r(s, a)$, and $v_b$ without estimating them separately — crucial since $p$ and $r$ are unknown in the RL settings.
Closed-Form Solution for $q_b^\pi$. We start from the actual definition of action values $q$.
\[\begin{align*} q_b(\pi, s, a) &= \lim_{t_{max}\to\infty} \mathbb E_{s_t\sim p(\cdot\mid s, a), a_t\sim \pi(\cdot\mid s, a)}\left[ \sum_{t=0}^{t_{max}-1} r(s_t, a_t)-v_g^\pi\mid \pi S_0=s, A_0=a \right] \\ q_b(\pi, s, a) &= \mathbb E_{s_t\sim p(\cdot\mid s, a), a_t\sim \pi(\cdot\mid s, a)}\left[ \sum_{t=0}^{\infty} r(s_t, a_t)-v_g^\pi\mid \pi S_0=s, A_0=a \right] \\ q_b(\pi, s, a) &= r(s, a) - v_g^\pi + \sum_{s'\in\mathcal S} p(s'\mid s, a) \mathbb E_{a\sim \pi(\cdot\mid s, a')}[q_b(\pi, s', a')] \\ q_b(\pi, s, a) &= (I-P_\pi)^{-1}(r_\pi- v_g^\pi\vec 1) \end{align*}\]$Q_\gamma$-Learning for Discounted Optimality. Where we use
\[\hat q_\gamma^{k+1}(s, a)\leftarrow (1-\beta)\hat q_\gamma^k(s, a) + \beta \left(r(s, a) + \gamma\max_{a'\in\mathcal A}\hat q_\gamma^k(s', a')\right)\]Alternatively
\[\hat q_\gamma^{k+1}(s, a)\leftarrow \hat q_\gamma^k(s, a) + \beta \left(r(s, a) + \gamma\max_{a'\in\mathcal A}\hat q_\gamma^k(s', a')-\hat q_\gamma^k(s, a)\right)\]$r(s, a)+\gamma\max_{a’\in\mathcal A}[\hat q_\gamma^k(s’, a’)]$ forms the Right-Hand Side (RHS) of the Bellman Optimality Equation (BOE $\gamma$ ) applied to $q_\gamma$.
Convergence criteria for $Q_\gamma$-Learning. Ideally, under the Bellman Optimality Equation (BOE $\gamma$), the difference between the RHS and LHS should be zero upon convergence. Mathematically, this can be expressed as:
\[\begin{align*} \lim_{k\to\infty} \left| r(s, a) + \gamma\max_{a'\in\mathcal A}[\hat q_\gamma^k(s', a')] - \hat q_\gamma^k(s, a) \right| = 0 \\ RHS - LHS = 0 \implies\text{ convergence of }\hat q_\gamma(s, a)\text{ to }q^\star_\gamma(s, a) \end{align*}\]Inexact Policy Evaluation
Inexact Policy Evaluation, avoiding the needs for transition probability. In DP setting, we can exactly evaluate a policy via $v_x(\pi, s)$ for arbitrar optimality criterion $x$. However, in RL settings, we have no access in transition probability $P$ and reward scheme $R$. Another problem is that tabular DP method require enumeration of state (or state-action) values which is infeasible for massive large state spaces.
Function Approximation. We approximate value function that can be classify into two categories, parametric and non-parametric.
Parametric Function Approximation. Fixed and finite number of parameters adjusted during learning process. Parametric can simply be broken down into Linear Function (in terms of parameter) and Non-linear Function (Decision Tree and Neural Network).
Non-Parametric Function Approximation. No fixed number of parameters, the complexity grows with the amount of data (KNN, Kernel Methods).
Linear Function Approximation. We define value function $\hat v(s;\vec w)$ as a linear function to approximate $v(s)$. We define feature vector $\vec f(s)\in R^n$ and parameter vector $\vec w\in R^n$.
\[\begin{align*} \hat v(s;\vec w) &= \vec w^T \vec f(s) \approx v(s) \\ \vec v &= F\vec w\quad\text{in Matrix Form} \end{align*}\]Where $\vec v\in R^{\vert\mathcal S\vert \times 1}, F\in R^{\vert\mathcal S\vert \times dim(\vec w)}.$ We then learn moving into optimization problem to find $\vec w$ by using optimality criterion $e(\vec w)$.
\[\vec w^\star = \arg\min_{\vec w\in R^n} e(\vec w)\]Where the optimiality criterion $e(\vec w)$ could be mean squared (MS) or projected Bellman (PB).
Linear Function Approximation with (Weighted) Mean Squared Error. We would have $p^\star(s)$ a stationary distribution over states that assigns a weight to each state with a motivation that some states will be visited more often than others. We define weighted mean squared error as
\[e_{MS}(w) = \mathbb E_{s\sim p^\star(s)}\left[\left(v(s) - \hat v(s;\vec w) \right)^2\right]\]In discrete state spaces, we can expand the expectation and write it down as:
\[\begin{align*} e_{MS}(w) &= \sum_{s\in\mathcal S} p^\star(s)\left(v(s) - \hat v(s;\vec w) \right)^2 \\ e_{MS}(w) &= \sum_{s\in\mathcal S} p^\star(s)\left(v(s) - w^Tf(s)\right)^2 \\ e_{MS}(w) &= (v_\pi - F\vec w)^T D_{p^\star} (v_\pi-F\vec w) \end{align*}\]Where $D_{p^\star}$ is a diagonal matrix with $p^\star(s)$ on the diagonal.
To obtain optimal $w^\star$ that minimize MSE, we can use gradient descent.
\[\begin{align*} w &\leftarrow w - \alpha\nabla_w e_{MS}(w) \\ \nabla_w e_{MS} &= \nabla_w \mathbb E_{s\sim p^\star(s)}\left[\left(v(s) - \hat v(s;\vec w) \right)^2\right] \\ \nabla_w e_{MS} &= \mathbb E_{s\sim p^\star(s)}\left[\nabla_w \left(v(s) - \hat v(s;\vec w) \right)^2\right] \\ \nabla_w e_{MS} &= \mathbb E_{s\sim p^\star(s)}\left[2 \left(v(s) - \hat v(s;\vec w) \right)\cdot \nabla_w \hat v(s;\vec w) \right] \\ \nabla_w e_{MS} &= \mathbb E_{s\sim p^\star(s)}\left[2 \left(v(s) - \hat v(s;\vec w) \right)\cdot \nabla_w w^Tf(s) \right] \\ \nabla_w e_{MS} &= \mathbb E_{s\sim p^\star(s)}\left[2 \left(v(s) - \hat v(s;\vec w) \right)\cdot f(s) \right] \end{align*}\]Approximation of true $v(s)$ in RL settings. Since there are no training data (i.e true $v(s)$ is also unknown), we approximate this using TD or Monte Carlo (MC). We approximate using
\[v(s) \approx \mathbb E\left[ \{\underbrace{r(s, a) - \hat g + \hat v(s'; w)}_{\text{approximation of }v(s)\text{ from BEE}} - \hat v(s; w)\}f(s) \right]\]This involves the approximation of $\hat v(s; w)$, hence it’s bootstrapping (i.e using an estimation of a value to estimate another one). Because it is an expectation, it is sampling-friendly (i.e using sample of single interaction (s, a, r′, s′) to get the expectation approximation)
Inexact Policy Iteration
Policy Iteration with a Parametric Approach. Since in policy iteration there are two main components, policy evaluation and policy improvement, we could divide the approximation separately.
Approximate Policy Evaluation. We approximate $V^\pi$ or $Q^\pi$ depending which one we adopt. We define finite fixed parameter $w\in R^n$, thus $\hat V(s; w), \hat Q(s, a; w).$ The goal is to minimize error with the true value through similar processes, MSE or TD error. Sometimes we assume linear function approximation such that
\[\hat V(s; w) = \phi(s)^T w\]Where $\phi(s)\in R^n$ is a feature vector. Pretty identical to Inexact Value Iteration. Sometimes $n=\vert\mathcal S\vert$ becoming a one-hot vector.
Approximate Policy Improvement. Once we have sufficient accurate $\hat V(s)$ or $\hat Q(s, a)$, we perform policy improvement. We update $\pi$ (potentially parameterized to be $\pi(s; w’)$). In some scenarios, we might select an action a that maximizes $\hat Q(s, a; w)$ to yield a deterministic policy.
Identical process, error minimization through optimization. Both then define error criterion then optimize using gradient descent. Identical to Indexact Value Iteration and regular Machine Learning framework.
Value Approximation Criterion : Bellman Error and Projected Bellman Error
Above section explain the usage of MSE. Here we will explain the usage of PB. Here we will revisit Bellman Equation, defining bellman error, and then the solution proposed called Projected Bellman Error.
Bellman Equation revisit. The Bellman equation for a value function $v$ can be written in the form
\[\begin{align*} v(s) &= r(s) - g + \mathbb E[v(s')\mid s] \\ (I-P')v &= r-g\vec 1\quad\text{In Matrix Form} \end{align*}\]Bellman error measures how well a candidate value function $v$ satisfies the Bellman equation. Basically the difference between approximated $\hat v(s)$ and the true $v(s)$.
\[\begin{align*} \text{Bellman Error}(s) &= [r(s) - g+\mathbb E[v(s')\mid s]] - \hat v(s) \\ = (r-g\vec 1)+ P'v - \hat v(s) &= \vec 0\quad\text{In Optimal Matrix Form Scenario} \end{align*}\]When the Bellman error is zero for all states, $v$ exactly satisfies the Bellman equation.
Projected Bellman Error (PBE). Using BEE error, $v$ may lie in a restricted function space (e.g $v$ cannot be represented by $\hat v$ as an implication that we assume $\hat v$ is linear but actual $v$ is not for example). Hence, we cannot always solve in exact, we use projection operator $\Pi$ into our parameter space. Projected bellman error defined as
\[\text{PBE}(v) = \Pi\left[\underbrace{(r-g\vec 1)+P'v}_{\mathbb Bv}\right] - v\]Where $\mathbb Bv$ is the Bellman operator. We project bellman operation $\mathbb Bv$ into our parameter space $\vec w$.
Minimizing the PBE is a common strategy in methods such as LSTD, where we seek a parameterized value function $\hat v(w)$ that is as close as possible (in a projected sense) to the Bellman update.
How to perform projection $\Pi$. Suppose we have feature matrix $F\in R^{\vert\mathcal S\vert\times k}$ and diagonal weighting $D_{p^\star}\in R^{\vert\mathcal S\vert\times\vert\mathcal S\vert}.$ Each row in $F$ is a feature vector $f(s)^T\in R^k$ with diagonal in $D_{p^\star}$ represent stationary distribution over states. We wish to define a projection
\[\Pi : \mathbb R^{\vert\mathcal S\vert} \to \text{Col}(F)\]where $\text{Col}(F)$ is the column space spanned by $F$. The projection is taken under the $\ell_2$-norm weighted by $D_{p^\star}$ denoted as
\[\Vert x\Vert^2_{D_{p^\star}} = x^T D_{p^\star} x\]Formally, for any vector $v\in\mathbb R^{\vert S\vert}$, we want to satisfy
\[\Pi(v) = \arg\min_{x\in \text{Col}(F)} \Vert \mathbb v - x\Vert^2_{D_{p^\star}}\]Since $x\in \text{Col}(F)$ can be represented as $x=Fw$ for some $w\in R^k$, the problem becomes
\[\Pi(v) = \arg\min_{w\in R^k} \Vert \mathbb v - Fw\Vert^2_{D_{p^\star}}\]This becomes a least squares problem, and the solution is given by
\[\begin{align*} \nabla \Pi(v) &= 0 \\ \nabla_w (Fw-v)^TD_{p^\star}(Fw-v) &= 0 \\ F^T D_{p^\star}(Fw-v) + (Fw-v)^TD_{p^\star}F &= 0 \\ 2(Fw-v)^T D_{p^\star} F &= 0 \\ (w^TF^T-v^T) D_{p^\star} F &= 0 \\ w^TF^TD_{p^\star}F -v^TD_{p^\star} F &= 0 \\ w^TF^TD_{p^\star}F &= v^TD_{p^\star} F \\ F^TD_{p^\star}Fw &= F^TD_{p^\star}v \\ w &= (F^TD_{p^\star}F)^{-1} F^TD_{p^\star}v \\ \end{align*}\]The optimal projection then become
\[\Pi(v) = Fw = F(F^TD_{p^\star}F)^{-1} F^TD_{p^\star}v\]Deriving $w^\star$ to Minimize Projected Bellman Error (PBE). Above is general projection formula if we want to project $v$ into $\text{Col}(F)$. Now we want to project bellman operator on $v$ ($\mathbb B v$).
\[\begin{align*} \Pi[\mathbb Bv] = F(F^TD_{p^\star}F)^{-1} F^TD_{p^\star}\mathbb Bv \\ \Pi[\mathbb Bv] = F(F^TD_{p^\star}F)^{-1} F^TD_{p^\star}\mathbb [r - g\vec 1 + P'Fw] \\ \end{align*}\]Utilizing PBE Norm for Precise Objective. We want PBE $=\Pi[\mathbb Bv]- v = \vec 0$, since PBE is a vector, we would need to turn into scalar for optimization which we will use norm. Usually PBE = $\vec 0$ is impossible, we want to be as close as $\vec 0$ as possible. Weighted $\ell_2$ norm could be used.
\[\begin{align*} \Delta v(s) &= \hat v(s; w) - \Pi[\mathbb Bv(s;w)] \\ e_{PB} &= \Vert \Delta v \Vert^2_{p^\star} = \sum_s p^\star(s) [\Delta v(s)]^2 \end{align*}\]Full formula for $e_{PB}$.
\[\begin{align*} e_{PB} = \Vert Fw - F(F^TD_{p^\star}F)^{-1} F^TD_{p^\star}\mathbb [r - g\vec 1 + P'Fw] \Vert_{p^\star}^2 \end{align*}\]Under suitable assumption, invertibility of ${F^TD_{p^\star}(I-P’)F}^{-1}$, we could derive the closed form formuka (well known LSTD solution). It also could be solved using least square.
\[w^\star = \{F^TD_{p^\star}(I-P')F\}^{-1}F^TD_{p^\star}(r-g\vec 1)\]Main advantage, we do not need the true value function $v$. From these, we can construct the Bellman operator $\mathbb B$ (or an empirical version of it) and compare $\mathbb Bv$ to $v$. This approach is stable because it relies on the self-consistency property of the Bellman equation rather than on direct knowledge of true $v^\star$.
Connection with TD Error. Methods like Temporal Difference (TD) learning effectively estimate the Bellman error incrementally. A TD update can be viewed as trying to drive the quantity
\[\delta_t = r_t - g + v(s_{t+1}) - v(s_t)\]to zero over time, which corresponds to making $v$ satisfy the Bellman equation in expectation.
Value Approximation : Building Matrix $X$ Encoding Transition and Stationary Distribution in RL settings
Another technique for linear approximation of value function, Encoding Transition and Stationary Distribution. We will define $f(s)$ as a feature vector for state $s$, $p^\star(s)$ and $p(s’\mid s)$ stationary distribution and transition probability respectively. We will ended up as simple as solving System of linear equations $Xw=y$ later on.
Intuition of X. We want to build $X$ that encode effect of transition.
\[\begin{align*} v(s) &=r(s)-g+\mathbb E[v(s')\mid s] \\ v(s)-\mathbb E[v(s')\mid s]&=r(s)-g \\ Xw&=y \end{align*}\]We would like to encode the LHS of the above bellman equation.
Direct Definition of $X$. One way is to sum over all states $s$ and possible next statets $s’$ through outer product.
\[\begin{align*} X = \sum_s p^\star(s)\sum_{s'} p(s'\mid s)\left[f(s)f(s)-f(s)f(s')\right]^T \\ X = \sum_s p^\star(s)\sum_{s'} p(s'\mid s) f(s)\left[f(s)-f(s')\right]^T \end{align*}\]Note that $f(s)f(s)$ is an outer product that form matrix, $f(s)f(s)^T$, that capture pairwise interactions in feature vector. Lets define feature matrix $F\in R^{\vert\mathcal S\vert\times k}=[f(s)^T]_s$ as a matrix of feature vectors. Then we could write $X$ as :
\[\begin{align*} X &= \sum_s p^\star(s)\sum_{s'} p(s'\mid s) f(s)f(s)-\sum_s p^\star(s)\sum_{s'} p(s'\mid s) f(s)f(s') \\ X &= \sum_s f(s)p^\star(s)f(s) \sum_{s'} p(s'\mid s)-\sum_s f(s)p^\star(s) \sum_{s'} p(s'\mid s) f(s') \\ X &= F^T D_{p^\star} F I- F^T D_{p^\star} PF \\ X &= F^TD_{p^\star}(FI-PF) = F^TD_{p^\star}(IF-PF) \\ X &= F^TD_{p^\star}(I-P)F \end{align*}\]Definition of y. Continuing on average reward scenario, we could precisely define $y$ as.
\[\begin{align*} y &= \sum_s p^\star(s)[r(s)-g]f(s) \\ y &= F^T D_{p^\star} (r-g) \\ \end{align*}\]Where $r(s_i)$ is immediate reward, g could be discount factor or baseline. We multiply by $f(s_i)$ to lift (project) the scalar reward into same feature space.
Linear Equation Interpretation. We will have
\[Xw = y\]where $y$ is a vector derived from rewards or td-terms. If $X$ is non singular, $w = X^{-1}y$ typically represents the parameters of an approximate value function in RL.
Main Advantage, Sample-Based Approximation of X. Without sampling friendly of this formulation, solving $w=X^{-1}y$ will need $P$ and $D_{p^\star}$ which is not available in RL settings. $X$ is sample friendly due to direct expectation that could be approximated without involving $P, D_{p^\star}$ and $\vec r$ (r for all states). Even if we know them, computing $w$ is still infeasible for large state space and feature. \(\hat X = \frac{1}{n}\sum_{i=1}^n f(s_i)[f(s_i)f(s'_i)]^T\)
Similarly we could perform unbiased sample estimate for $y$.
\[\hat y = \frac{1}{n}\sum_{i=1}^n [r(s_i)-g] f(s_i)\]Both $\hat X, \hat y$ contructed as sample mean making them unbiased estimator for each $X, y$.
These are called Least Square Temporal Difference (LSTD) Solution solving TD fixed-point equation. Where we solve $\hat w = \hat X^{-1}\hat y$ where both $\hat X, \hat y$ using sample estimate. We often add regularization term to the matrix to force it singular.
\[\hat w = (\hat X + \epsilon I)^{-1}\hat y\]This technique usually called L2-regularization in the context of LSTD.
Special Feature Vector as One Hot Encoding Case. Where $F=I$ or $f(s)=e_s\in R^{\vert\mathcal S\vert}$ where $e_s=1$ if $i=s$ else $0$. This raise dimensionality issues since dimension of w has to match this. Another implication is that solving $Xw=y$ is equivalent to solving exact value of each state. So LSTD or TD(0) in this case reduce to solving well-known tabular forms showing that tabular method simply special case for linear approximator with one-hot feature space.
Inexact Policy Improvement : Policy Gradient
Goal of Policy Improvement. In policy improvement, we want to find better policy $\pi^{k+1}$ under some optimality criterion $v$ such that
\[v(\pi^{k+1}) \ge v(\pi^k)\]Remember that in Policy iteration, we seek improvement, not optimal policy under $v$.
Policy Gradient Methods. The idea is to perform gradient ascent on the objective function $v_x(\pi)$ where $x$ indicates the chosen optimality criterion (e.g., discounted return, average reward, total reward, or bias). It is formulated as
\[\pi^{k+1} \leftarrow \pi^{k} + \alpha \nabla_\pi v_x(\pi^{k})\]Challenge is Computing the Gradient of $v$ wrt $\pi$, Direct Policy Parameterization vs Explicit Policy Parameterization. A direct application of this concept, called direct policy parameterization, attempts to compute partial derivatives of $v_x(\pi)$ with respect to the policy $\pi$ itself. However, this approach is challenging since
- Policy may not be simple differentiable form
- Directly working in the space of all possible policy can be extremely high dimensional
These challenges motivate an alternative known as explicit policy parameterization.
Motivation for Explicit Policy Parameterization. We introduce parameter vector $\theta\in\Theta\subseteq \mathbb R^d$ for arbitrary $d$. Then we defined family of policy in parameter space $\pi_\theta(a\mid s)$. Thus, the value function could be written as $v(\pi_\theta) = v(\theta)$. This way we could compute gradient of $v(\pi_\theta)$ with respect to $\theta$ with advantage of
- Flexible High-Dimensional Function Approximation, we could use neural network or simple linear regression one
- Systematic Exploration Control, stochastic parameterization can naturally incorporate exploration
- Compatibility with Gradient-Based Optimization, powerful optimization algorithms can be applied
- Empirical Success in State-of-the-Art Algorithm, many of the best-performing RL algorithms in continuous control and high-dimensional settings rely on explicit policy parameterization.
Policy Parameterization for Discrete Action Spaces
Policy Parameterization for Discrete Action Spaces. We parameterize $\pi(a\mid s; \theta)$ as a categorical distribution which commonly approached by using softmax parameteriation.
\[\pi(a\mid s; \theta) = \frac{\exp(\theta^T \phi(s, a))}{\sum_{a'\in\mathcal A}\exp(\theta^T \phi(s, a'))}\]Where $\phi(s, a’)$ is a feature vector for state-action pair. Since $\log \pi(a\mid s;\theta)\propto\pi(a\mid s;\theta)$ (optimizing for $\log \pi$ equivalent of optimizing for $\pi$), we could choose to optimize for $\log\pi$ for numerical stability that is commonly use.
\[\nabla_\theta \log \pi(a\mid s; \theta) = \phi(s, a) - \sum_{a'\in\mathcal A}\pi(a'\mid s; \theta)\phi(s, a')\]This expression is essential for computing the policy gradient in REINFORCE and actor-critic methods.
Computing $\nabla_\theta v(\theta)$. The policy gradient theorem states that
\(\nabla_\theta v(\theta) = \sum_{s\in\mathcal S} p^\star(s)\sum_{a\in\mathcal A} q^{\pi_\theta}(s, a)\nabla_\theta \pi_\theta(a\mid s;\theta)\)
So the gradient of value function is the weighted sum of $q^{\pi_\theta}(s, a)$ with weight $\pi_\theta(a\mid s;\theta)$.
Approximating Gradient through Sample Mean. Since stationary distribution $p^\star$ is unknown, we use sample mean to approximate the gradient in RL settings. For each ${(s_t, a_t, r_t)}$ we observe, we take the approximation as
\[\nabla_\theta v(\theta) \approx \frac{1}{n}\sum_{i=1}^n q^{\pi_\theta}(s, a)\nabla_\theta \pi_\theta(a\mid s; \theta)\]If $q^{\pi_\theta}(s, a)$ is replaced by an unbiased return estimate (e.g., Monte Carlo returns, bootstrapped estimates, or advantage functions), then equation above is an unbiased stochastic gradient of $v(\theta)$.
Semi-Stochastic Approach in Practice. In practice, some approximations introduce bias. For instance, $q^{\pi_\theta}(s, a)$ may be approximated by a learned critic or truncated returns. Moreover, during learning, $\theta$ may change faster than we can gather fully on-policy samples. This mismatch between the policy used to gather data and the updated policy parameters can create a semi-stochastic gradient approach. While theoretically these approximations may introduce some bias, in many real-world tasks they are sufficiently accurate to yield strong performance and stable learning
In Summary about Policy Gradient.
- Inexact but Monotonically Improving: Each update step aims to increase $v(\theta)$.
- Unbiased or Semi-Unbiased Estimates: Depending on how $q^{\pi_\theta}(s, a)$ is estimated, the gradient update may be unbiased (e.g., Monte Carlo returns) or partially biased (e.g., bootstrapped estimates, off-policy data).
- Computational Feasibility: Sampling-based methods are often the only viable approach in high-dimensional or continuous RL problems.
- Compatibility with Practical Hyperparameters: Even if the procedure is not strictly on-policy or if there is some mismatch in distributions, these methods still tend to work well in practice.
Discounted Reward Policy Gradient
Discounted Reward and the Policy Gradient Theorem. Revise the definition of the discounted reward objective
\[J(\theta) = \mathbb E_{\pi_\theta}\left[\sum_{t=0}^\infty \gamma^t R_{t+1} \right] = P^\star_\pi r_\pi\]Where $P^\star_\pi = (I-\gamma P_\pi)^{-1}$ is the discounted resolvent (the total discounted visitation across time).
Defining Discounted State Distribution. To capture how much each state contributes to the return, accounting for discounting. We define discounted state distribution as
\[\mu_\gamma(s) = (1-\gamma)\sum_{t=0}^\infty \gamma^t \Pr(S_t=s)\]We multiply by $1-\gamma$ to make this sum a proper probability distribution. This corresponds to a geometric distribution over state visitation (trial until first success). This reflects that recent states are weighted more heavily than distant ones.
How to Properly Sample a State from the Discounted Distribution. Let $\mu_\gamma$ denote the normalized (since we multiply by $1-\gamma$) discounted state.
- Sample a length $L\sim Geo(1-\gamma)$, representing number of steps to run in the episode
- Run trajectory from $t=0$ to $t=L-1$ and let the sampled state be $S_{L-1}$
In practice, people often use all states ${S_0, \dots, S_{L-1}}$ to construct an unbiased gradient estimate more efficiently.
Gradient of the Discounted Performance. When differentiating the performance objective with respect to parameters $\theta$, a challenge arises:
- $\nabla_\theta \mu_\gamma(s)$ is unknown
- $\nabla_\theta \mu_\gamma(s)$ is not sampling friendly
To be precise, we are looking into the following expression
\[\nabla_\theta v_\gamma^\pi(s) = \sum_{s\in\mathcal S} P^\gamma_\pi(s\mid s_0)\sum_{a\in\mathcal A} q_\gamma^\pi(s, a)\nabla_\theta \log \pi(a\mid s;\theta)\]Note that $r$ is incorporated inside $q$. The discounted transition $P^\gamma_\pi$ is not a proper probability distribution. And the dependency on future state visitation makes it difficult to sampling since it relies on off-policy like expectations over future trajectories.
The Policy Gradient Theorem. Despite the problem above, we can still derive useful result.
\[\begin{align*} \nabla J(\theta) &= \nabla_\theta v_\gamma^\pi(s) \propto \sum_{s\in\mathcal S}\mu_\gamma(s)\sum_{a\in\mathcal A}\nabla_\theta\pi(a\mid s;\theta)q^\pi(s, a) \end{align*}\]Where the gradient does not involve $\nabla_\theta \mu_\gamma(s)$, and the proportionality constant depends on $\gamma$. This result allows us to construct stochastic estimates of the policy gradient using sample trajectories.
Sampling-Friendly Estimation of Policy Gradient Theorem. Keep this in mind since we will see this formulation in almost every SOTA policy gradient algorithm. We can rewrite the gradient as
\[\begin{align*} \nabla J(\theta) &= \mathbb E_\pi[q^\pi(s, a)\nabla_\theta\log\pi(a\mid s;\theta)] \\ \nabla J(\theta) &= \mathbb E_{s, a\sim\pi}[\text{reward signal}\cdot \nabla_\theta\log\pi(a\mid s; \theta)] \end{align*}\]See the different that in standard gradient ascent, we the hill directly (where is the lower and where is the higher on a single point), here, we estimate the hill that will be very noisy and delayed using reward signal. Which forms the basis of REINFORCE and other policy gradient algorithms.
REINFORCE Algorithm with Discounted Return. In practice, for episodic tasks, we define the update rule as:
\[\theta_{t+1} = \theta_t + \alpha G_t\nabla_\theta\log\pi(A_t\mid S_t; \theta_t)\]Where $G_t=\sum_{k=t}^T\gamma^{k-t}R_{k+1}$ is monte carlo discounted return (if sampled approximated). This form emphasizes the timeweighted contribution of each reward.
Variance Reduction in Policy Gradient
High Variance in Policy Gradient Methods. While the standard estimator of policy gradient theorem $\mathbb E[q(S, A)\nabla\log\pi(A\mid S)]$ is unbiased, it can have high variance.
Two common strategy to reducing it without introducing bias are
- Using baseline (or control variate) that is independent of the action
- Employing an actor-critic approach, which leverages learned value functions.
Baseline as a Control Variate. A control variate is a technique from statistics used to reduce the variance of an estimator without adding bias. We define $b(S)$ that does not depend on action $A$ so that it leaves the expected gradient unbiased
\[\begin{align*} J(\theta) &=\mathbb E[(q^\pi(S, A)-b(S))\nabla\log\pi(A\mid S;\theta)] \\ &=\mathbb E_{a\sim\pi}[q^\pi(S, A)\nabla\log\pi(A\mid S;\theta)] - b(S)\mathbb E_{a\sim \pi}[\nabla\log\pi(A\mid S;\theta)] \\ &=\mathbb E_{a\sim\pi}[q^\pi(S, A)\nabla\log\pi(A\mid S;\theta)] \\ &= \mathbb E_{a\sim\pi}[\{q^\pi(S, A)-b(S)\}\nabla\log\pi(A\mid S;\theta)] \\ &= \mathbb E_{a\sim\pi}[A^\pi(s, a)\nabla\log\pi(A\mid S;\theta)] \\ \end{align*}\]Since $\mathbb E_{a\sim\pi}\nabla\log\pi(A\mid S;\theta)=0$, second terms disappear leaving the estimate unbiased. However, the variance reduced significantly by a good choice of $b(S)$. We called $A^\pi(s, a)$ as the advantage function that is flexible to design.
Advantage Function Example. One common example is $b(s)=V^\pi(s)$ that yield
\[\begin{align*} A^\pi(s, a) &= q^\pi(s, a)-v^\pi(s) \\ J(\theta) &= \mathbb E_{a\sim\pi}[\{q^\pi(S, A)-v^\pi(S)\}\nabla\log\pi(A\mid S;\theta)] \end{align*}\]The advantage function indicates how much better or worse an action $a$ is relative to the average value of state $s$.
Actor-Critic. Consist of two components, actor that update policy parameter $\theta$ via gradient ascent and critic that estimates value function $v^\pi$ or $q^\pi$ used as baselines to reduce variance. Because the critic can learn $V_\pi(s)$ (or $Q_\pi(s, a)$) online using data, it provides an adaptive baseline that improves over time, helping the actor’s updates become more stable.
Critic Example, Temporal-Difference (TD) Learning. Seen in many actor-critic method. We will utilize TD target for $v^\pi(s)$
\[\begin{align*} \\ v^\pi(s, a) &= r_{t+1} + \gamma v^\pi(s_{t+1}) \implies \delta_t = r_{t+1} + \gamma v^\pi(s_{t+1}) - v^\pi(s, a) \\ J(\theta) &= \mathbb E[\delta_t] \implies \nabla_\theta J(\theta) = \mathbb E[-\delta_t] \\ v^\pi(s_t)&\leftarrow v^\pi(s_t) + \alpha(r_{t+1}+\gamma v^\pi(s_{t+1})-v^\pi(s_t)) \end{align*}\]Note that we want to minimize td error $\delta_t$, it seems like we did gradient ascent (which to maximize) which a wrong way of seeing it, the sign flipped because of negative gradient. Although single-step TD target can introduce bias, it converges to the true value function thus serves as an unbiased estimator in the limit.
Using a Parametric Critic to Reduce Variance Further. Many policy gradient methods incorporate a parametric critic to approximate the value function or the action-value function.
Baseline via Parametric Value Function. If we choose $b(s)=v_{critic}(s;w)$ as the baseline, then the policy gradient update becomes
\[\nabla_\theta v^\pi(s) \approx (q^\pi(s, a)-v_{critic}(s;w))\nabla_\theta\log\pi(a\mid s;\theta)\]where $q^\pi(s, a)-v_{critic}(s;w)$ is an approximate advantage. In practice, $q^\pi(s, a)$ itself often replaced by critic estimate $q_{critic}(s, a;w)$.
Actor Critic: Single Samples Updates. Each transition $(S, A, R, S’)$ can be used to
- Update the critic parameter $w$ (e.g via temporal-difference learning above), aiming to improve $Q_{critic}(s, a;w)$ and $V_{critic}(s;w)$.
- Update the actor parameter $\theta$ using the critic’s estimates to form a low variance gradient update
Combining Baseline and Actor-Critic. We often employ both a baseline and an actor-critic approach:
- The baseline ensures that subtracting something like $v_{critic}(s; w)$ does not introduce bias but can substantially reduce variance.
- The actor-critic ensures that this baseline (or the action-value approximation) is adaptively learned via single-sample updates (e.g., using TD methods).
Instead of only subtracting a static baseline, we can directly learn and refine $Q_{critic}(s, a; w)$ (or $V_{critic}(s; w)$) to compute advantage $A_t^\pi$. This approach typically converges faster and is more stable than using Monte Carlo returns (REINFORCE Algorithm) for the baseline.
Benefit of Parametric Critic. By maintaining a parameterized function $Q_{critic}(s, a; w)$ or $V_{critic}(s; w)$, the method can:
- Provide continuous improvement in baseline quality, thus continually adaptively reducing variance.
- Combine seamlessly with neural network approximations, allowing scalability to large state-action spaces.
Sensitivity of Optimal Policy
Essence of Each Optimality Criterin. Average reward often associated with a stationary state distribution that we believe exists and will converge. Discounted reward apply discount factor $\gamma$ to future rewards imply that there is a probability $(1-\gamma)$ of terminating at each step thus placing more emphasis on recent states.
Dependency on the Initial State Distribution. Different initial state distribution might lead into different optimal policy. Thus the ideal way of writing policy is to separate $\pi^\star_0$ (for a particular initial distribution) and $\pi_p^\star$ (for the initial distribution $p$).
Deep RL
Recall GPI in Policy Gradient.
Vanilla Policy Gradient.
- Init $\theta^{k=0}$
- for $k=0, 1, \dots$, evaluate and improve.
- Evaluate $v_x(\pi(\theta^k))$
- Improve
Intro to TPRO. We define advantage $A(s, a)=q(s, a)-v(s, a)$.
\[\begin{align} \mathbb E_{S\sim p^\star_{\pi'}}[A^\pi(S, A)] &= \sum_s\sum_a p^\star_{\pi'}(s)\pi'(a\mid s)[r(s, a)-v^\pi_g+\sum_{s'}p(s'\mid s, a)v^\pi(s')-v^\pi(s)] \\ &= v_g(\pi')-v_g(\pi) + 0 \end{align}\]for another policy $\pi\neq\pi’$. We interpret this as, the expectation of advantage is the gain different between $\pi’$ and $\pi$. We use this fact for policy improvement / critic.
\[\theta^{k+1}\leftarrow \arg\max\left\{ \mathbb E_{p^\star_{\pi_\theta}}[a^{\theta^k}] = v_g^\theta-v_g^{\theta^{k+1}} \right\}\]The problem is that, we need to sample with respect to new policy with parameter $\theta$. We need to modify the above such that it involve $p_{\theta^k}$.
\[\begin{align} v^\theta_g-v^{\theta^k}_g - \mathbb E[a^{\theta^k}] = \vert p^\star_\theta(s) - p^\star_{\theta^k}(s) \vert \\ \le \max_s\vert\mathbb E[a^{\theta^k}]\vert \cdot \sum_s\vert p^\star_\theta(s) - p^\star_{\theta^k}(s)\vert \\ (k_{max}-1)\sqrt{2\mathbb E[\Delta_{KL}(\theta, \theta^k, s)]} \end{align}\]TODO: Derive TRPO formula
…
Importance sampling.
\[\begin{align} \mathbb E[a^{\theta^k}] = (\theta-\theta^k)^T \nabla\mathbb E_{\pi_{\theta}}[ a^{\theta^k}] \\ \mathbb E[a^{\theta^k}] = (\theta-\theta^k)^T \nabla\mathbb E_{\pi_{\theta^k}}[\frac{...}{...} a^{\theta^k}] \\ \end{align}\]TODO: Kemeneng constant
Algorithm Summary
Policy Iteration Algorithm, Exact Average Reward.
- Initialize iteration index and random starting policy $k=0, \pi_0$
- Exact Policy Evaluation : Obtain $v_b$ through closed form or solve BEE SLE
- Exact Policy Improvement : Update $\pi_k$ to be greedy wrt $v_b$. See equation below.
- Check for convergence : check if current $v_b$ is the same as before, otherwise repeat 2.
Policy Iteration Implementation Considerations.
- Handling multiple optimal policies: The algorithm should be modified to handle multiple optimal policies. If multiple optimal policies exist, the algorithm may switch back and forth between them indefinitely. By knowing that only single optimal $v_b^\star$ and $v_g^\star$, we could use this as the convergence criteria instead.
- Synchronous updates: Updating $\pi^{k+1}$ for all possible states is called synchronous update. In RL, asynchronous updates are often used for large state space.
- Stable policy: Stability is achieved when the policy no longer changes for all states. If one or more state changes, then the policy is still evolving and not yet stable.
Value Iteration Algorithm, An Alternative to Exact Policy Iteration. Policy Iteration relies on the Bellman Expectation Equation (BEE) to iteratively evaluate and improve a policy, Value Iteration leverages the Bellman Optimality Equation (BOE) to directly compute the optimal value function. Value Iteration avoids the need for explicit policy evaluation steps, making it a more straightforward approach.
- Initialize: iteration number, initial value function, and tolerance ($k=0, v_g^{k=0}(s)=0, \epsilon>0$)
- Update Value $v_g^k$: using equation below
- Check Convergence : $span(\hat v_b^{k+1} - \hat v_b)>\epsilon$, where $span(v)=\max_s v(s)-\min_s v(s)$ if yes repeat 2 else continue to 4
- Output Greedy Policy : $\pi_g^\star\in\arg\max_{a\in\mathcal A}[r(s, a)+\mathbb E_{s’\sim p(\cdot\mid s, a)} \hat v_b(s’)]$
Value Iteration Implementation Issue. One issue with Exact Value Iteration is that Step 2 is not contractive, which means that $v_b^{k+1}$ may diverge/explode. To address this, we introduce the Exact Relative Value Iteration algorithm. The solution is Exact Relative Iteration
Exact Relative Value Iteration $v_b$ (in DP Settings).
- Initialize: iteration number, value function for reference state, tolerance, reference state ($k=0, v_g^{k=0}(s)=0, \epsilon>0, s_{ref}\in\mathcal S$)
- Update Value $v_g^k$: using reference state written on equation below
- Check Convergence : $span(\hat v_b^{k+1} - \hat v_b)>\epsilon$, where $span(v)=\max_s v(s)-\min_s v(s)$ if yes repeat 2 else continue to 4
- Output Greedy Policy : $\pi_g^\star\in\arg\max_{a\in\mathcal A}[r(s, a)+\mathbb E_{s’\sim p(\cdot\mid s, a)} \hat v_b(s’)]$
Exact Relative Value Iteration $q_b$ (in DP Settings).
- Initialize: iteration number, value function, tolerance and reference state $(k, q_b^{k=0}(s, a)=0, \epsilon>0, s_{ref}\in\mathcal S)$
- Update value $q_b^{k+1}$: using reference state written on equation below
- Check Convergence, if yes repeat 2 else 4
- Output Greedy Policy : $\pi_g^\star\in\arg\max_{a\in\mathcal A}[r(s, a)+\mathbb E_{s’\sim p(\cdot\mid s, a), a’\sim \pi(\cdot\mid s, a)} \hat q_b(s’, a’)]$
Where $\max_{a’\in\mathcal A}[\hat q_b^{k}(s’, a’)]$ is an approximation of $v_b^\star(s)$ and $\max_{a’‘\in\mathcal A}[\hat q_b^{k}(s_{ref}, a’’)]$ is an approximation of $v_b^\star(s_{ref})$
Algorithm Summary
Dynamic Programming (DP) Methods
-
Setting: Model-based (known transition probabilities $P(s’ \mid s, a)$ and reward function $r(s, a)$)
-
Key Assumption: Complete knowledge of the MDP dynamics
-
Policy Evaluation (PE). Computes the value function for a given policy by iteratively applying the Bellman expectation equation:
- Policy Improvement (PI). Creates a better policy by acting greedily with respect to the current value function:
- Policy Iteration. Alternates between policy evaluation and policy improvement until convergence:
- Initialize policy $\pi$ arbitrarily
- Policy Evaluation: Compute $v^\pi$ precisely
- Policy Improvement: Compute $\pi’$ from $v^\pi$
- If $\pi’ = \pi$, return optimal policy $\pi^*$; otherwise set $\pi \leftarrow \pi’$ and go to step 2
- Value Iteration. Combines policy evaluation and improvement into a single update:
Mental Model: DP methods learn from complete knowledge of the MDP dynamics, making them particularly effective for tasks where the dynamics are known.
Monte Carlo (MC) Methods
-
Setting: Model-free, episodic environments
-
Key Assumption: Access to complete episodes, but no knowledge of transition dynamics
-
First-Visit MC. Updates value function based on the first visit to a state in each episode:
Where $G_t = \sum_{k=0}^{T-t-1} \gamma^k R_{t+k+1}$ is the return from time $t$ until the episode terminates at time $T$.
-
Every-Visit MC. Similar to first-visit, but updates based on every visit to a state in an episode.
- MC Control with Exploring Starts. Combines MC policy evaluation with policy improvement:
- Initialize arbitrary policy $\pi$ and value function $Q(s,a)$
- Generate episode using exploring starts (begin in random state-action pairs)
- For each $(s,a)$ in the episode, update $Q(s,a)$ toward the return $G_t$
- Improve policy: $\pi(s) = \arg\max_a Q(s,a)$
- Mental Model: MC methods learn from experience by averaging returns from complete episodes, making them particularly effective for episodic tasks where gathering complete trajectories is feasible.
Temporal-Difference (TD) Learning
-
Setting: Model-free, can work in both episodic and continuing tasks
-
Key Assumption: No knowledge of dynamics, but can bootstrap from incomplete episodes
-
TD(0) for Policy Evaluation. Updates value estimates toward a bootstrapped target:
Where $r_{t+1} + \gamma V(s_{t+1})$ is the TD target and $r_{t+1} + \gamma V(s_{t+1}) - V(s_t)$ is the TD error $\delta_t$.
- SARSA (On-Policy TD Control). Updates Q-values using the current policy’s next action:
- Q-Learning (Off-Policy TD Control). Updates Q-values using the maximum next action value, regardless of the policy followed:
- Q-Learning for Discounted Return ($Q_\gamma$-Learning). Specifically optimizes for discounted returns in the off-policy setting:
- Mental Model: TD methods blend ideas from MC and DP—they learn from experience like MC but bootstrap like DP, allowing for online, incremental learning without requiring complete episodes.
Function Approximation Methods
-
Setting: Large or continuous state spaces where tabular methods become impractical
-
Least-Squares Temporal Difference (LSTD). Uses linear function approximation with feature vectors:
Where:
- $\hat{X} = \sum_i f(s_i)[f(s_i)-\gamma f(s’_i)]^T$
- $\hat{y} = \sum_i r_i f(s_i)$
- $f(s)$ is the feature vector for state $s$
-
$\epsilon$ is a regularization parameter
- Mental Model: Function approximation methods generalize experience across similar states, enabling reinforcement learning in complex environments where enumerating all states is impossible.
Policy Approximation Methods
-
Setting: Continuous action spaces or where stochastic policies are beneficial
-
Policy Gradient (REINFORCE). Directly optimizes policy parameters via gradient ascent:
Where $G_t$ is the return from time step $t$.
- Policy Gradient with Baseline. Reduces variance by subtracting a baseline value:
Common baseline: $b(s) = V(s)$, the state value function.
-
Actor-Critic Methods. Combine policy gradient (actor) with value function approximation (critic):
-
Critic: Updates value function via TD learning \(v_w(s) \leftarrow v_w(s) + \alpha_v \delta_t \nabla_w v_w(s)\)
-
Actor: Updates policy parameters using critic’s value estimates \(\theta \leftarrow \theta + \alpha_\theta \delta_t \nabla_\theta \log \pi_\theta(a_t|s_t)\)
Where $\delta_t = r_{t+1} + \gamma v_w(s_{t+1}) - v_w(s_t)$ is the TD error.
-
-
Mental Model: Policy-based methods directly optimize the policy, avoiding the limitations of value-based approaches in continuous action spaces and naturally handling stochastic policies.
Important Takeaways
RL Algorithm Selection Framework:
- If model is known: Use Dynamic Programming methods
- For efficiency: Value Iteration
- For policy stability: Policy Iteration
- If model is unknown (model-free):
- For episodic tasks with manageable episodes: Monte Carlo methods
- For continuing tasks or when bootstrapping is beneficial: TD methods
- For off-policy learning: Q-Learning
- For continuous action spaces: Policy Gradient methods
- For reduced variance: Actor-Critic methods
- For large state/action spaces:
- Linear approximation: LSTD
- Non-linear approximation: Deep RL methods (DQN, DDPG, PPO, etc.)
Remember: The core insight across all RL algorithms is finding the balance between exploration (gathering information) and exploitation (maximizing reward), while effectively handling the credit assignment problem (which actions led to which outcomes).